



After publication My recent article on how to estimate the cost of the OpenAi API, I received an interesting comment that someone had noticed that the OPENAI API is much more expensive in other languages, such as those using Chinese, Japanese or Korean characters (CJK), than in English.
tiktoken libraryI was not aware of this problem, but I quickly realized that it is an active research field: at the beginning of this year, an article called “Tokenizers of the language model introduced the injustice between the “Petrov et al languages”. (2) have shown that the “same text translated into different languages can have considerably different Tokenization duration, with differences up to 15 times in some cases. “”
As recycling, tokenization is the process of dividing a text into a list of tokens, which are common sequences of characters in a text.
The difference in token length is a problem because The OPENAI API is billed in units of 1,000 tokens. So, if you have up to 15 times more tokens in a comparable text, this will result in 15 times the costs of the API.
Experience: number of tokens in different languages
Trafions The phrase “Hello World” in Japanese (こんにちは世界) and let’s transcribe it into Hindi (हैलो हैलो). When we token new sentences with the cl100k_base Tokenzer used in OPENAI GPT models, we get the following results (you can find the Code I used for these experiences at the end of this article):

cl100k_base) For the “Hello World” sentence in English, Japanese and HindiFrom the above graph, we can make two interesting observations:
- The number of letters for this sentence is the highest in English and the lowest in Hindi, but the number of resulting tokens is the lowest in English but the highest in Hindi.
- In Hindi, there are more tokens than there are letters.
How can it happen?
Fundamental
To understand why we find ourselves with more tokens for the same sentence in languages other than English, we must review two fundamental concepts of coding of bytes and unicode pairs.
Encoding the pair of bytes
The byte pair coding algorithm (BPE) was initially invented as a guarantee compression algorithm (1) in 1994.
“The algorithm (BPE) compresses the data by finding the most frequent pairs of bytes in the data and replace all the instances of the pair with an byte which was not in the original data. The algorithm repeats this process until no other compression is possible, either because there are no more frequent pairs that occur or there are no more unused bytes to represent the pairs . “(1)
Let us pass like the original paper (1). Let’s say you have the smallest text corpus made up of the “ababcabcd” channel.
- For each pair of bytes (in this example, characters), you count its occurrences in the corpus as indicated below.
"ABABCABCD"
pairs = {
'AB' : 3,
'BA' : 1,
'BC' : 2,
'CA' : 1,
'CD' : 1,
} - Take the pair of bytes with the greatest number of occurrences and replace it with an unused character. In this case, we will replace the “AB” pair with “X”.
# Replace "AB" with "X" in "ABABCABCD":
"XXCXCD"
pairs = {
'XX' : 1,
'XC' : 2,
'CX' : 1,
'CD' : 1,
}- Repeat step 2 until no other compression is possible or no more unused bytes (in this example, characters) are available.
# Replace "XC" with "Y" in "XXCXCD":
"XYYD"
pairs = {
'XY' : 1,
'YY' : 1,
'YD' : 1,
}Unicode
Unicode is a coding standard that defines how the different characters are represented in unique numbers called code points. In this article, we are not going to cover all the details of Unicode. Here is a Excellent Stackoverflow answer If you need a refreshment.
What you should know about the following explanation is that if your text is coded in UTF-8, the characters of different languages will require different quantities of bytes.
As you can see in the table below, the letters of the English language can be represented with ASCII characters and require only 1 byte. But, for example, the Greek characters require 2 bytes, and the Japanese characters require 3 bytes.

Look under the hood
Now that we understand that the characters of different languages require different quantities of bytes to be represented digitally and that the tokenzer used by the GPT models of OpenAi is a BPE algorithm, which, which, token at the byte level, has a more look deep on our opening experience.
English
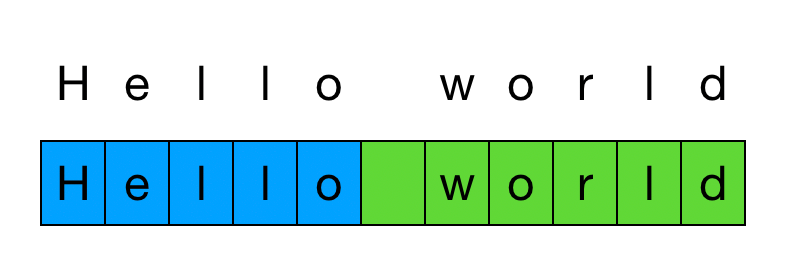
First of all, let’s look at the example of vanilla tokenization in English:

According to the above visualization, we can make the following observations:
- A letter is equivalent to a code point
- A unicode code point is equivalent to 1 byte
- The tokenise BPE 5 bytes for “Hello” and 6 bytes for “world” in two separate tokens
This observation corresponds to the declaration on the Openai’s tokenizer site::
“A useful golden rule is that a token generally corresponds to ~ 4 characters of the text for the common English text.”
Note how that said “for the common English text”? Let’s look at the texts that are not English.
Japanese
Now, what happens in the languages in which a letter does not correspond to an byte but to several bytes? Let’s look at the “Hello World” sentence translated into Japanese, which uses CJK characters that make 3 bytes in the UTF-8 coding:

According to the above visualization, we can make the following observations:
- A letter is equivalent to a code point
- A unicode code point is equivalent to 3 bytes
- The tokenise BPE 15 bytes for こんにちは (Japanese for “hello”) in a single token
- But the letter 界 is tokenized in a single token
- The letter 世 is tokenized in two tokens
Hindi
It goes even more crazy in languages where a letter does not equal a point of code but is made of several code points. Let’s look at the expression “Hello World” transcribed into Hindi. The Devanāgarī alphabet used for Hindi has characters which must be divided into several code points with each point of code requiring 3 bytes:

According to the above visualization, we can make the following observations:
- A letter can be made up of several unicode code points (for example, the letter है is made by combining code points ह and ै)
- A unicode code point is equivalent to 3 bytes
- Likewise to the Japanese letter 世, a point of code can be divided into two tokens
- Some tokens cover more than one but less than two letters (for example, ID of token 31584)
Summary
This article explored how the same “Hello World” sentence translated into Japanese and transcribed into Hindi is tokenized. First of all, we learned that the tokenzer used in OPENAI GPT models at the byte level. In addition, we have seen that the Japanese and Devanāgarī characters require more than one byte to represent a character unlike English. Thus, we have seen that the UFT-8 coding and the BPE tokens will play a big role in the number of tokens that results in and has an impact on the costs of the API.
Of course, different factors, such as the fact that GPT models are not also trained on multilingual texts, influence tokenization. At the time of writing the writing moment, this problem is an active field of research, and I am curious to see different solutions.
Have you enjoyed this story?
Subscribe for free To be informed when I publish a new story.
Find me on Liendin,, TwitterAnd Bother!
References
Image references
If not indicated otherwise, all images are created by the author.
Web and literature
(1) Gage, P. (1994). A new algorithm for data compression. C User Journal,, 12(2), 23–38.
(2) Petrov, A., La Malfa, E., Torr, Ph, & Bibi, A. (2023). Language model tokenseurs introduce injustice between languages. Arxiv Prementation Arxiv: 2305.15425.
Code
This is the code I used to calculate the number of tokens and decode the tokens of this article.
# pip install tiktoken
import tiktoken
# Define encoding
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
# Tokenize text and get token ids
tokens = encoding.encode(text)
# Decode token ids
decoded_text = (encoding.decode_single_token_bytes(token) for token in tokens)